

Create beautiful, AI-optimized docs that automatically adapt to your users and drive conversion






























More than 30,000 teams trust GitBook to power their docs
Browse our showcase or send us a link to your public docs and we’ll create a personalized preview.
Simplify your docs workflow and help your users succeed
GitBook gives you everything you need to create unbeatable docs — with a workflow that your whole team will recognize, and insights to measure success
Collaborate and build in a git-based workflow
Collaborate on docs like you collaborate on code. Work in branches, and let your team edit where they want — whether that’s GitBook’s editor or their IDE.
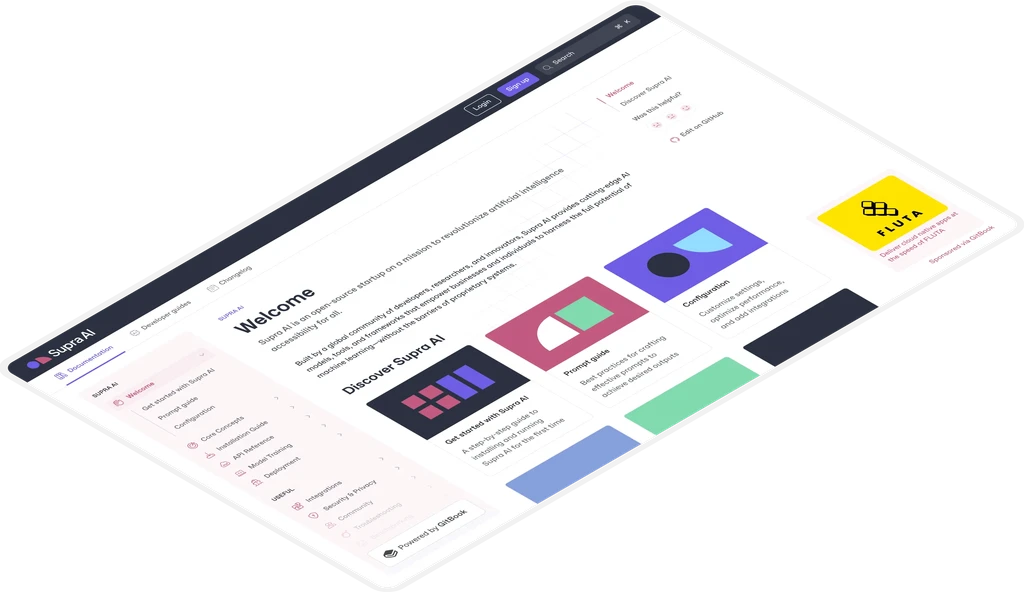
A modern block-based editor
GitBook’s block-based WYSIWYG editor supports code blocks, tables, and more. Plus it includes Markdown support and integrations for your favorite tools.


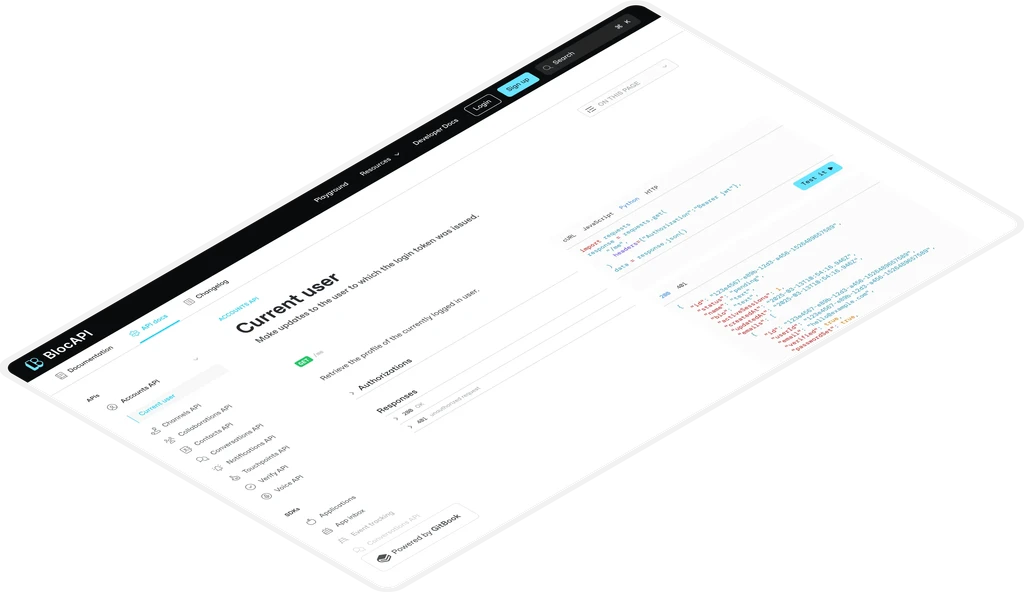
Seamless sync with GitHub & GitLab
Sync your docs with a Git repo so everyone can contribute — or just edit in GitBook. Either way, the branch-based workflow helps you collaborate and maintain quality.
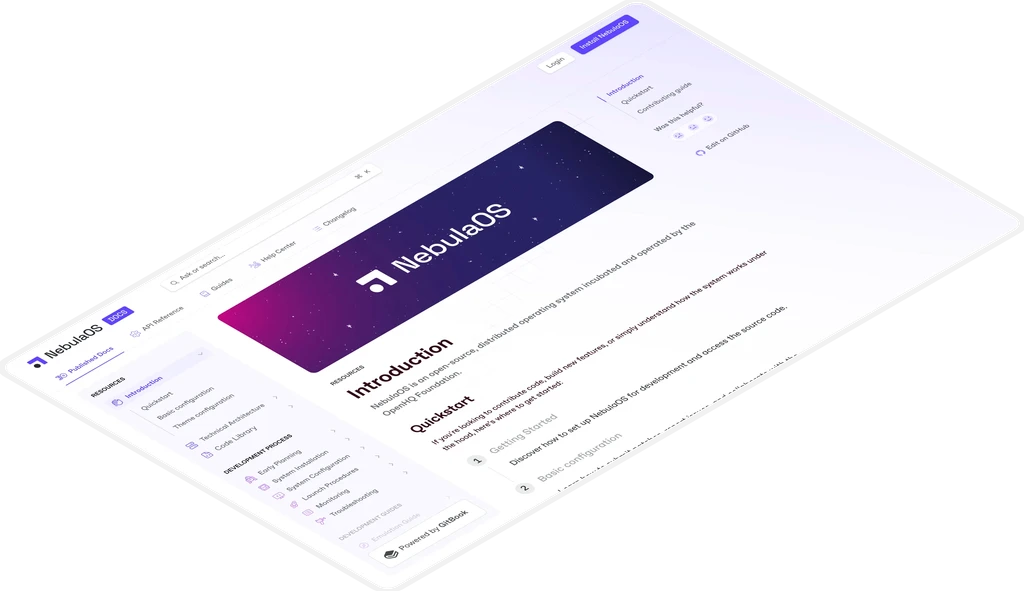
Publish beautiful, fully-hosted docs
Effortlessly migrate your docs to GitBook, add your own branding, and publish in a click. Docs published with GitBook are automatically optimized for SEO and AI data ingestion.
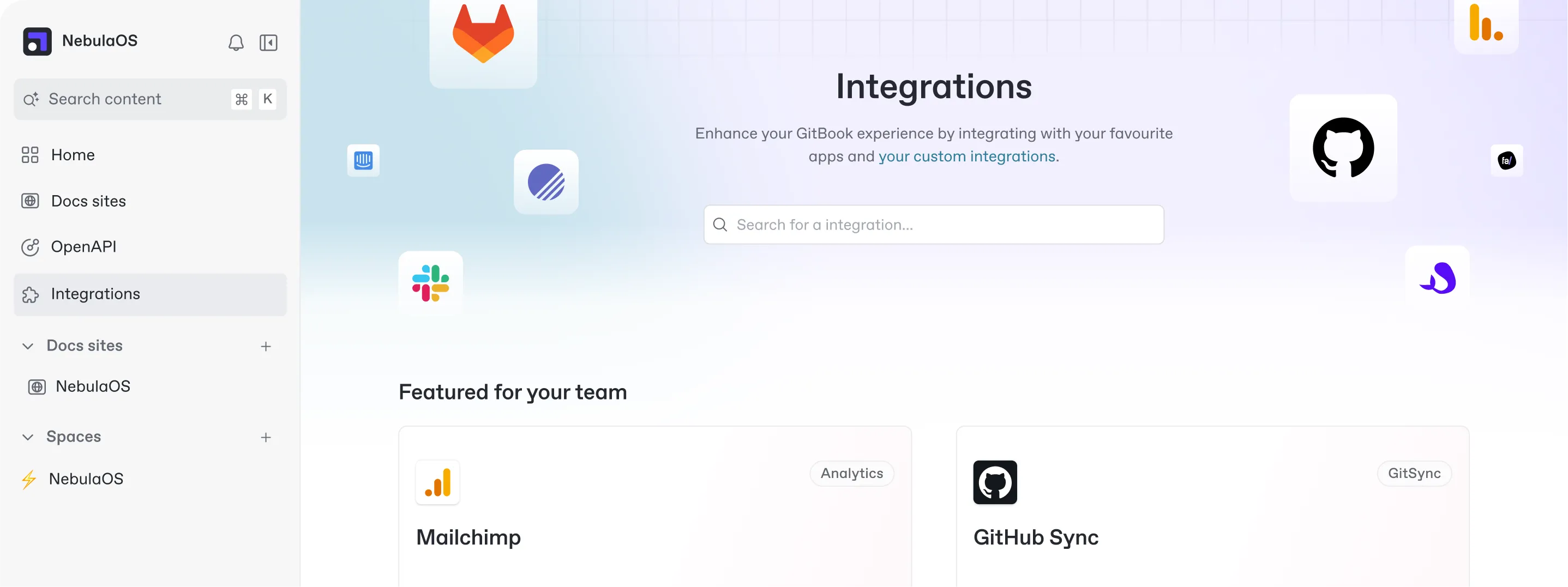
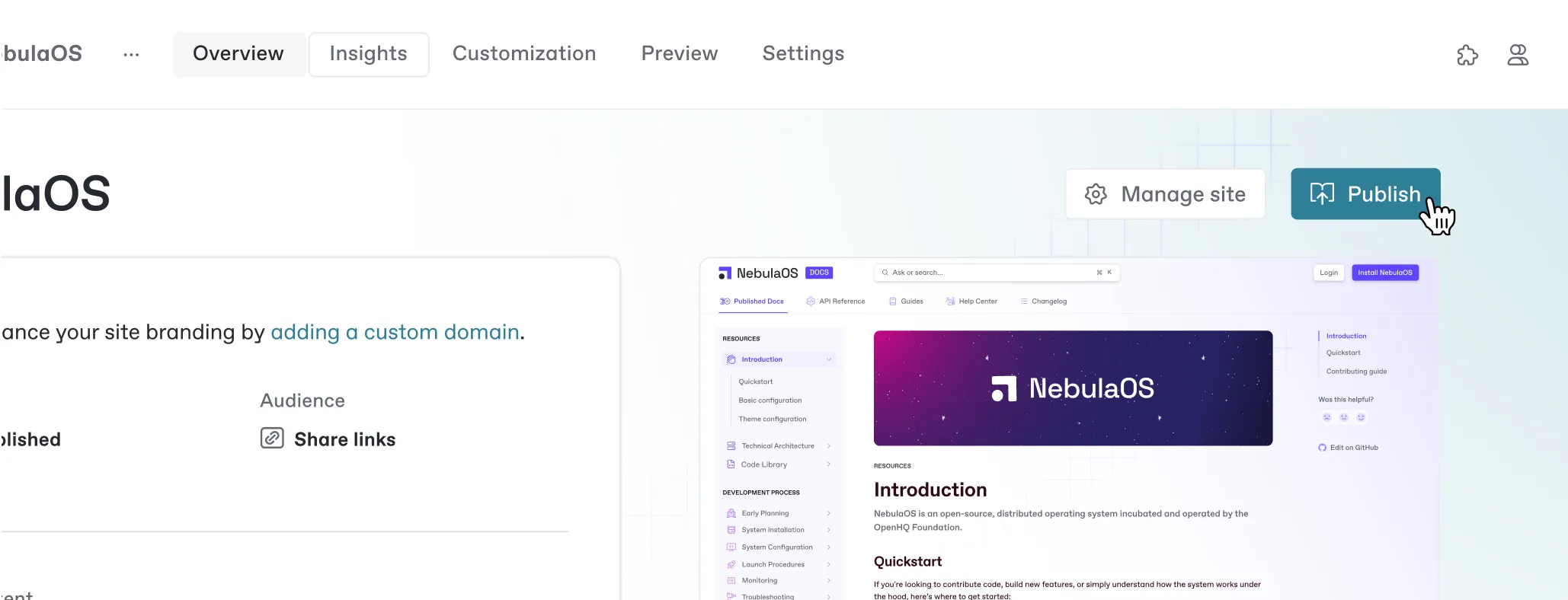

Powerful publishing tools
Create a seamless experience between your docs and product
Integrate your documentation right into your product experience, or give users a personalized experience that gives them what they need faster
Deliver a personalized docs experience for every user
With adaptive content, your docs can utilize user information to offer an experience that is specific to them.
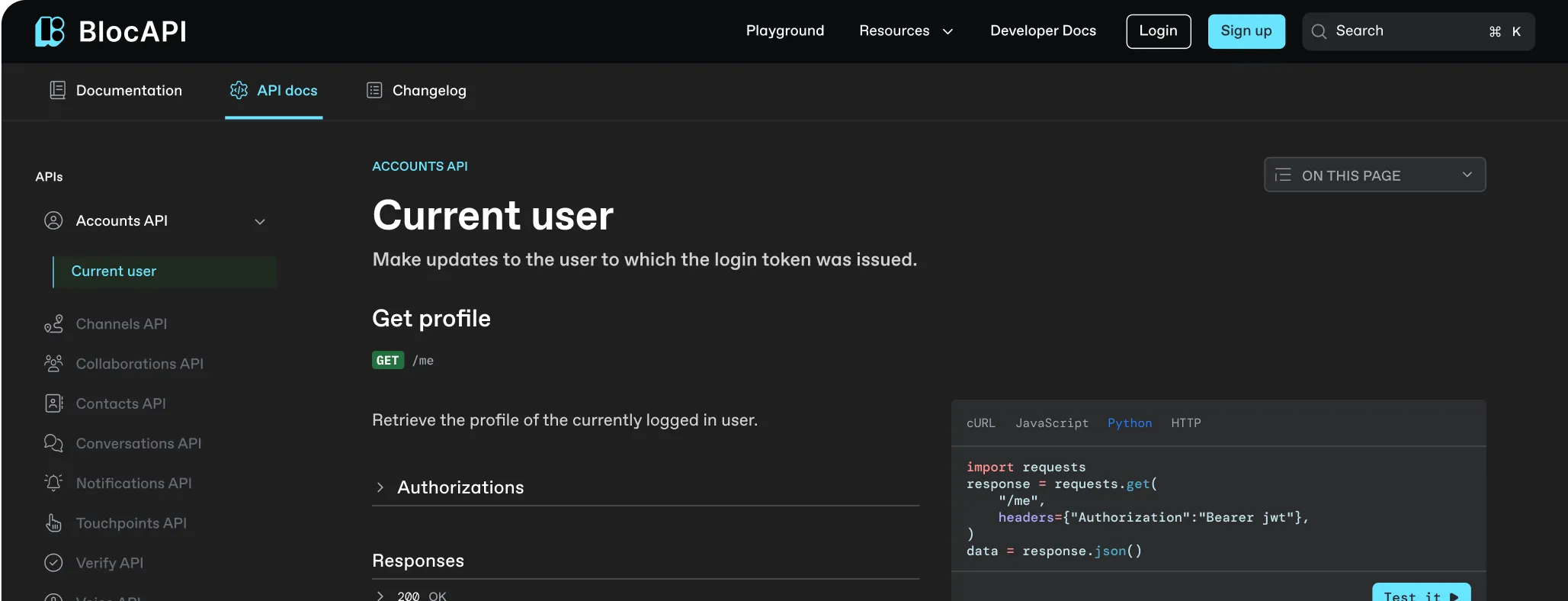
Pre-fill API keys within interactive reference docs
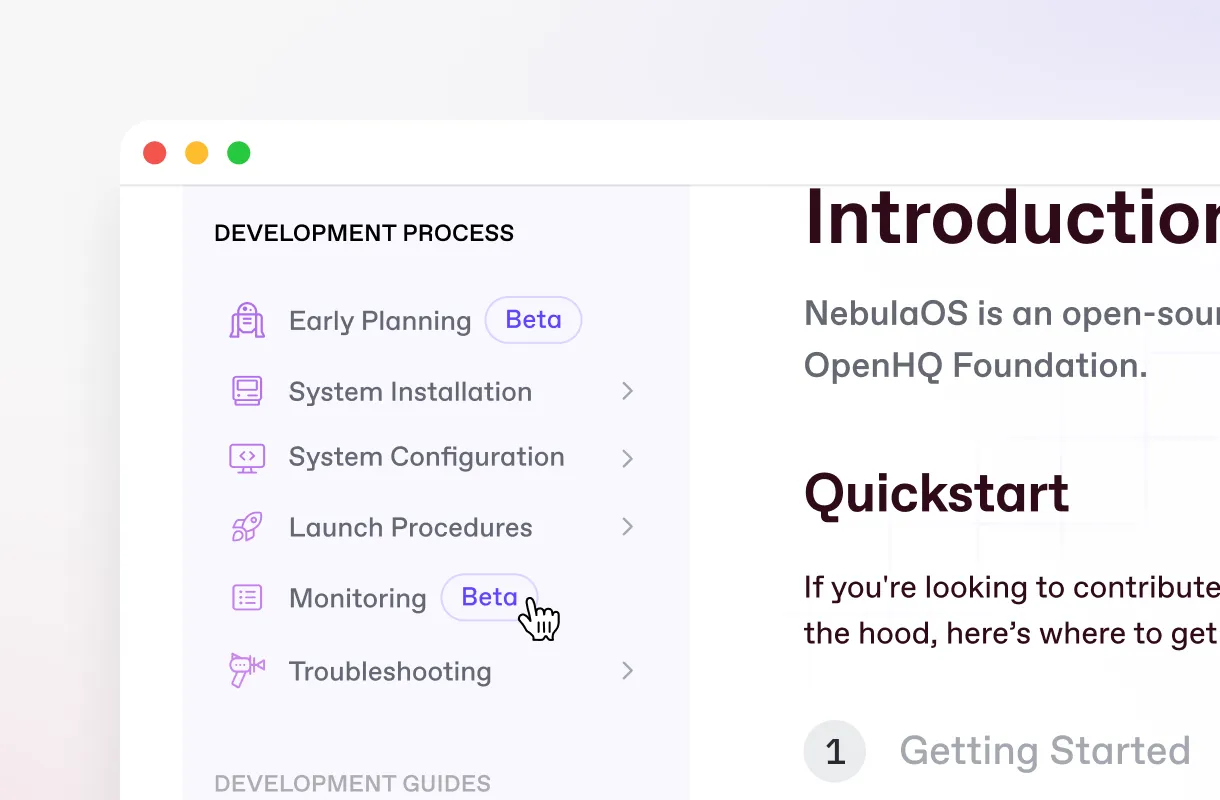
Link docs access to product feature flags
Hide beta docs from everyone but beta testers
Show ’Upgrade’ buttons to users on lower pricing tiers
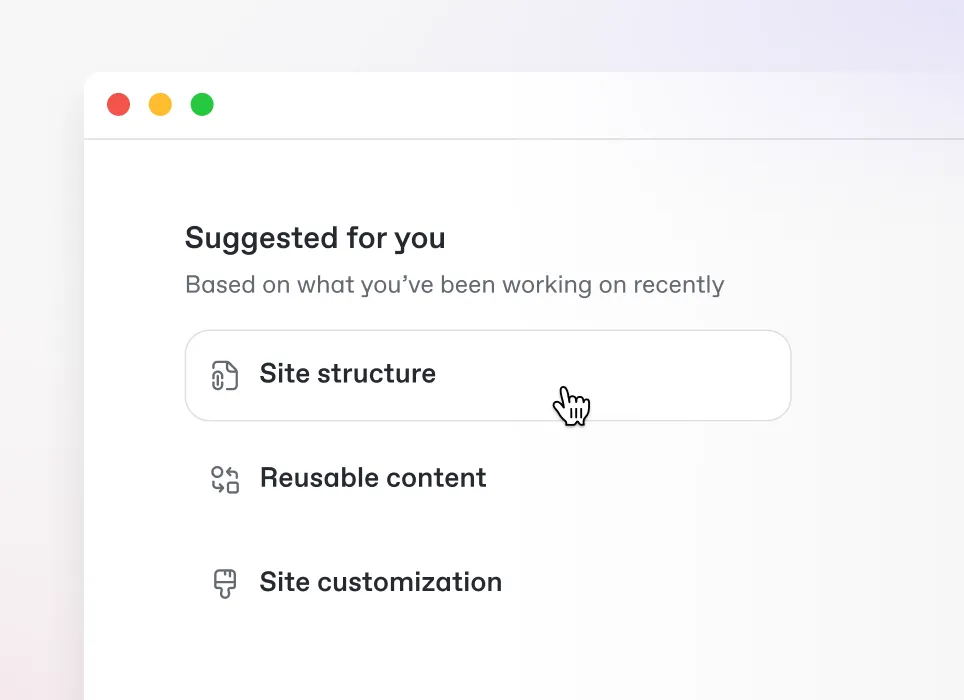
Recommendations based on product interactions
When your docs site knows what product features your users have access to or were recently using, your docs can suggest relevant content automatically.
Suggest docs based on recent product actions
Highlight onboarding guides for new customers
Surface guides for a flow your user didn’t complete
Spotlight docs for features you want users to enable
The next generation of documentation
Built-in analytics
Track metrics for your GitBook site using the built-in insights panel. So you can show how useful great docs really are.
Increase your docs’ impact
Connect docs updates to product releases to show improved user experience and impact on key metrics like signups, conversion, ticket reduction and more.
New software shouldn’t take a year to implement
Here's what you can achieve with GitBook in just one week
Today
Sync your docs with GitHub
Import your content and upload your API in 5 minutes
Publish your first docs site
Day 2
Invite your team in 2 minutes
Customize your docs’ colors, logos and branding
Add sections and structure
Day 7
Add translations to your docs
Measure the impact of your docs with built-in insights
Docs convert 2x more than marketing site

Trusted by leading technical product teams
